It is mostly acknowledged that developers should generally be responsible for their code on every stage of its lifecycle. Solving engineering problems involves not just coding, but testing, deploying, debugging, monitoring, and support. Thanks to the devops movement, this view is more of a mainstream nowadays (although in the context of this post I’d rather use a term engineering culture instead of devops). Edsger Dijkstra might have phrased this better:
It is a mistake to think that programmers wares are programs. Programmers have to produce trustworthy solutions and present it in the form of cogent arguments. Programs source code is just the accompanying material to which these arguments are to be applied to.
Nevertheless, I regularly notice that developers misunderstand and underestimate the responsibility they carry. Some think that having a code work on their machine is enough to consider a job to be done. That fixing and preventing issues in production is none of their business. Or that error handling, monitoring, and graceful degradation are some magical, extra efforts that only special “devops” people do. The others are simply unaware of the complexities of real world and of the differences between a production environment and their local setup.
This post is mostly for and about the latter. From the viewpoint of a web/backend developer, we’ll review a few common things that can go wrong in production, which usually are overlooked in a local environment. The discussion will be broad and somewhat shallow, but there are references to a more in-depth content in each section. In no way this post is exhaustive, but still I would have been glad to get my hands on these notes at the beginning of my career.
Table of contents:
Things that can go wrong
1. Human errors
We begin with an simple, maybe even boring category of incidents first, because they are as pervasive as they are easy to prevent in the hindsight. “Human errors”, in my understanding, include a variety of little things that devs tend to forget before releasing their code:
- Adding configuration files or variables for the production environment
- Setting up cron tasks and daemons
- Running migration scripts
- Basic sanity-checking
These issues usually arise when the deployment process consists of multiple steps which haven’t been coordinated properly. It is generally expected that a continuous delivery system (such as jenkins or gitlab) is supposed to manage the release with a single button or command. In practice though, the feature to be released might be too complex to be deployed automatically. It might require a simultaneous release of several projects, manual execution of migration scripts, tweaking production environment, and so on. This is when human factor comes into play, allowing a plenty of room for mistakes.
How to prevent human errors: While it might be tempting to keep everything in mind, I recommend to document any deployment process that consists of two or more steps. It doesn’t have to be elaborate, but it should be spelled out as a series of simple steps.
For more complex scenarios, a detailed release plan explaining the dependencies between the steps and a possible rollback strategy is a must.
To learn more, check out an article on Production readiness by Jaana Dogan.
2. Unexpected environment
A code doesn’t just run by itself. It depends, among other things, on the operating system and its configuration, the other software and libraries on the machine. Oftentimes we spend considerable efforts tuning things on our development machine to make everything work nicely, but forget about that when it comes to deployment, or recon it’s no longer our responsibility.
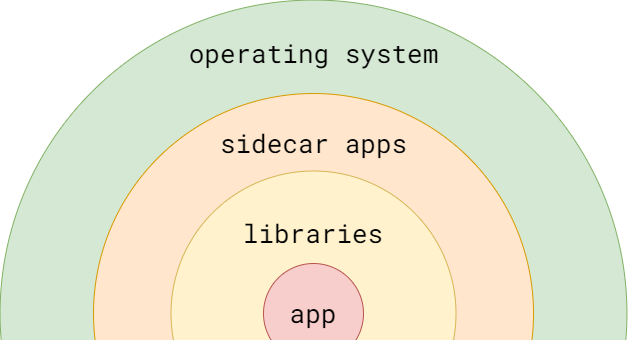
Layers of application environment
We usually consider the application, a central piece of the diagram above, to be a an ultimate outcome of our work. However, the outer layers of its environment require control and care too.
In interpreted languages, the application comes along with its libraries (like node_modules for javascript, for example) that aren’t usually kept with the source code, so we have to handle their delivery and versioning separately.
Next come additional dependencies and services that are supposed to run alongside a primary application, labelled as “sidecar apps” on the diagram. Programs in Java or PHP, for example, require a VM or an interpreter on the machine where they run. Or, when working with mongodb, it is recommended to spin up a mongos instance close to your code to proxy database queries through it.
The outer layer of software environment is the operating system, its configuration, and system libraries needed to run the service. Applications may have varying and loose requirements for those: some can run almost anywhere, while the others may be locked to a specific version of, say, linux or libc.
When preparing a software for deployment, the requirements for every layer must be considered. In my experience though, the further a layer is from the core application, the higher a chance that a programmer won’t account for it, or won’t consider themselves in a position to do so. Indeed, in most companies software engineers aren’t responsible for configuring operating systems in production. But I argue that at least understanding and documenting the environment requirements is a responsibility of a good software engineer anyway. Otherwise, a chance of ending up in a “works on my machine” situation just because you forgot to configure some external dependency becomes embarrassingly high.
How to handle unexpected environments:
While there is no single (nor simple) solution, I believe the developers should aspire to
- Make the environment reproducible.
- Ensure the development environment stays as close to the production as possible.
- Test in production.
Containerization is a mainstream solution when it comes to the first two points. It has become so widespread in the recent years, I will not even spend time describing it in details. But while bringing containers into your workflow may actually settle the question of reproducibility, it comes with its own cost. Managing containers is not easy, and the abundance and complexity of the tools to do that is quite overwhelming.
Sometimes, it might be enough to just document the requirements of your software and share it with your team. That is especially true if there are no designated people around to handle the infrastructural burden of virtualization. Also, this simple approach should work well if your project is small or if you are just starting to learn how everything works. When doing so, it is fine to do things manually and incrementally, rather than go all the way kubernetes at once. I think advice like “automate everything and never SSH to a server”, when given to a beginner, might actually do more harm than good by focusing too much attention on the abstractions and tooling.
And what about testing in production? The thing is, there is no way a testing/development environment could match production exactly. Yes, even if everything runs in containers or identical VMs. Even when software components of the environment are exactly the same, the infrastructure level below them (see next section for details) can’t be. That’s why it is important to have ways of running and testing your services in production, while not affecting the real users. A starting point in that direction could be creating a separate application instance that is only available from a private domain or with a special cookie (such an instance is usually called “staging” or “pre-production”). Then make sure important features are tested on that instance before being released.
To learn more:
- Read up on “infrastructure as code” approach and try out different tools like docker, ansible, terraform, to make your environment reproducible. Go incrementally and study the documentation.
- “I test in prod”, a piece on increment.com acknowledging that some kinds of problems can only be revealed in production.
- A series of articles “Testing in production, the safe way” by Cindy Sridharan is a great place to dig deeper into the subject.
3. Unexpected infrastructure
Outside of a software environment, there’s a world of hardware and networks, that can (unsurprisingly) also cause a variety of incidents. Software developers tend to neglect that, because usually their local infrastructure looks like this:

In such a setup, there is practically zero chance of facing the issues that happen in production all the time. Things like network congestion or disruption, latency spikes, proxy misconfiguration, DNS are all too easy to forget about. It is tempting to think everything will forever run smoothly and error-free as it does on a local machine.
Sure, the diagram I’ve pictured is simplistic; your development setup might actually be more advanced and involve actual networking. Still, it is generally quite stable and homogenous.
The real production infrastructure though is much more complex:
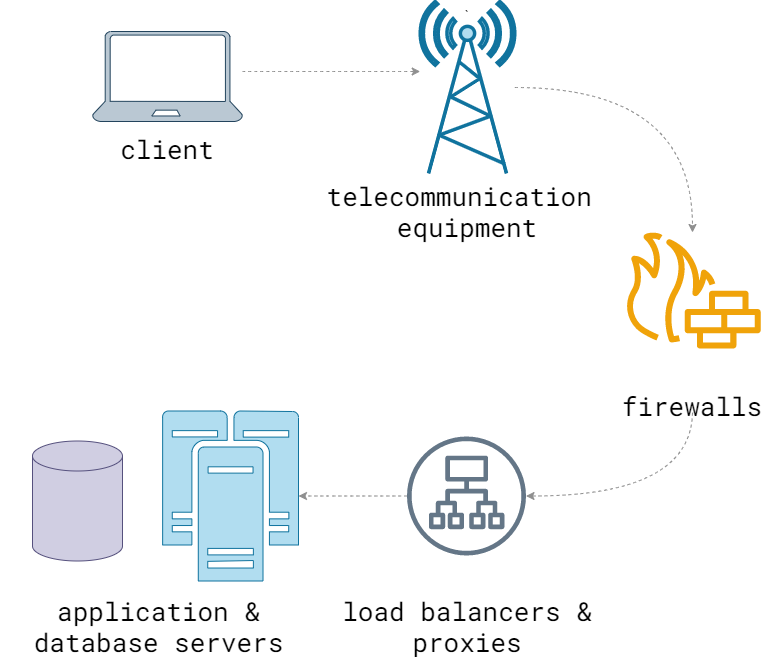
This is again a simplification, but it conveys the idea that there are many intermediate nodes between client and server: routers, cell towers, proxies, you name it. What’s worse is that the path of every user is often unique: starting with a device they use, ending with an ISP and VPN they’re connected to. It means different users might experience different issues that are hard to reproduce. Lastly, the real “server” is not a single entity, but a collection of services interconnected via the network, subject to faults of their own.
Clearly, unexpected faults can happen on every step of the diagram above, and we can’t just abstract from them completely. The abstractions we build around network and hardware are, while valuable, sometimes cloud the judgement and instill a false sense of security (this is not to say all abstractions are bad, but that they are oftentimes leaky). A responsible developer should be able to see through that, identify the potential obstacles and program accordingly.
The good news is that many of those things in between the clients and servers are usually managed by someone else (like an ISP). Thanks to the evolution of telecommunication technologies in the last century, the outages on that level are rare (by the way, we probably have much to learn from people in that field). So we mostly have to pay attention to the points where our software interfaces with the outside world: in the case of backend engineering, these are the load-balancers, webservers, DNS and such. Again, one might think those are not exactly within a scope of a software developer. But let’s take a look at just a few examples of how lower-level details leak into the application layer:
-
Configuration of timeouts and retries for remote calls. If request timeouts are not configured, most systems default to using infinite values, inevitably leading to the accumulation of zombie connections and processes hogging server resources. If timeouts are configured, it is often unclear how to handle them when they are triggered, because it is unknown whether a timed-out request has been delivered and processed. What can make the situation worse is adding retries to your remote calls without testing their behavior properly. Nowadays, this complexity tends to be moved into the realm of proxies and service meshes that promise to handle it automagically. However, those also need to be configured carefully, with an intuition of how the underlying systems work.
-
Cross-domain requests, iframe policies, cookie configuration, and other security-related concerns. These are easy to dismiss when everything works just fine on local domains. Also, easy to screw the security up by mindlessly allowing everything everywhere. A personal example: we’re running a group of websites with a single sign-on authentication, that happen to share the same second-level domain in test (say,
product-a.company.organdproduct-b.company.org), but not in production. In a setup like this, the authentication issues caused by cookie misconfiguration (such asSameSiteattribute) might become an unpleasant surprise for developers who think that domain names are none of their concern. -
Healthcheck implementation. When working with tools like haproxy and kubernetes, it is a good practice to configure healthcheck probes, which allow to monitor your application and take faulty instances out of service. Developers tend to implement these probes as an afterthought, and often don’t test their behavior locally. This can lead either to inability to detect unhealthy instances in production (if the healthchecks are too simplistic), or to cascading failures (if the healthchecks verify too many dependencies).
How to handle infrastructure problems:
- Learn the basic principles of computer networks, operating systems, Internet, DNS.
- Make yourself familiar with utilities like
ping,host,tcpdumpand how they work under the hood. - Test negative scenarios and introduce failures into your application to see how it behaves before it reaches production. Don’t just mindlessly throw log statements around in error handlers, but test them too. Because what is worse than a lack of an error handler is an error handler that errors while trying to handle the original error.
- If there are systems administrators in your company, then make sure to communicate with them. You are working towards a shared goal of keeping your services stable, and learning from each other helps a lot.
- If there are no sysadmins around, then you should probably become one (metaphorically speaking). Learning the basics of systems administration will boost your skills and help improve quality of the product you’re working on.
To learn more:
- Network protocols for anyone who knows a programming language on destroyallsoftware.com - a great introductory article into computer networks. (The posts on this website are paywalled, but I found this specific link shared publicly by someone, so hopefully it is alright to do the same.)
- The Amazon Builders' Library: Challenges with distributed systems
- Mechanical Sympathy: Understanding the Hardware Makes You a Better Developer
- (A few) Ops Lessons We All Learn The Hard Way
- Why you should understand (a little) about TCP by Julia Evans (there’s a lot of cool stuff on her blog, check it out!)
4. Unexpected users
People who use our products are very different from those who create them.
Technologically, client devices are usually less powerful than those where the service is developed. They are also much further from the server, their internet connection is imperfect, and latencies vary wildly. Those are well-known facts that nevertheless rarely attract developers attention, which in turn frequently leads to works on my machine situations. For example, even knowing that the network is unreliable, it at times feels daunting to reproduce and work around the specific ways in which it can be manifested.
From a behavioral standpoint, we tend to forget how unpredictable the users are. It is tempting to try and explain their actions in terms of “user stories”, but those are far too mechanistic and simplified to be a good model. Also, the more experienced a developer is, the stronger biases they acquire with regard to user interfaces. I, for example, subconsciously expect and avoid bugs in any software I use. I don’t begin interaction until the interface is fully loaded, don’t click important buttons twice, don’t refresh the page while awaiting response, don’t expect forms to treat my inputs carefully. But actual people do all those things (and much more).
Some users also want to break stuff on purpose, but regardless of that, we usually underestimate the countless ways they can break it accidentally. Failing to consider a user behavior can lead to all sorts of bugs caught too late: from trivial usability issues to double-charging, just because someone managed to press a “Pay” button twice.
Another thing to consider is user experience with adblock and similar browser extensions. Personally, to be able to really feel the products I work on, I whitelist them in extension settings. However, to be safe, it is better to test the websites both with and without adblock. Blocking ads is not an exact science: I’ve seen such extensions break page layouts, hide important content, and mess with javascript. Considering that 25% of the users have adblock enabled, you probably don’t want to risk that happening.
How to handle unexpected user behavior:
- Make sure the important buttons cannot be pressed twice or while the request is in-flight.
- Better yet, make important actions idempotent.
- Observe how non-technical people, like friends and family, use various apps and services. Don’t correct them when they “do things wrong”, instead make sure things can’t go wrong in your product.
- Collect the client-side errors and maybe look into real user monitoring.
- Use emulation modes like “Slow 3G” in browser console (and its equivalents in mobile apps) while testing your products.
5. Unexpected state
I came up with this umbrella term for a variety of bugs: from those related to the memory management in your programming language, to database consistency and caching issues. A shared trait among them is that they are hard to reproduce and to find a root cause for. They tend to manifest in a wide spectrum of symptoms, that might confuse a beginner and give misleading clues as to how to fix them.

Bugs related to application state are often hard to diagnose and reproduce
Let’s take a closer look at some of them:
5.1 Unexpected state: application memory
Speaking of back-end development, there are a few common ways of how HTTP requests are processed, depending on a web server and a programming language being used.
There’s a “one process per request” model, implemented in languages like PHP. PHP developers usually assume they can do anything in their programs: everything is scoped to just one request, so memory manipulations (such as changing global variables) may not affect other clients. This approach has its pros and cons which won’t be discussed here; what’s important to understand is that this is not a universal behavior.
Then, there’s a threading model, wherein a single application process (or a few of them) handle multiple requests concurrently, using OS threads or a custom “green threads” implementation. In this case, a part of a request handler’s memory may be (and probably will be) shared among many such handlers, thus requiring extra care when manipulating it. For example, when learning Go with PHP background, it is tempting to assume your HTTP request handlers run isolated from each other. On the contrary though, the whole application state outside of a handler callback is shared among all such callbacks. In Go, it means that changing global state within a single handler not only affects other clients, but also causes data races if appropriate concurrency primitives, such as channels and mutexes, aren’t used correctly. The same also applies to many other languages, although each of them has its own considerations and quirks.
A somewhat more advanced mistake developers make when breaking out of a “process-per-request” architecture is a desire to put shared application state to a good use. It is tempting to cache some data in a shared memory, or even use it like a database. This might work well in a development environment, until the application is deployed to production, where one finds out that…
- …there are many instances of a service running at once. Each of them ends up with its own isolated cache, so the clients receive stale data when their request hits another instance.
- …applications crash unexpectedly for a whole lot of reasons. Usually, supervisors like systemd or kubernetes take care of restarting them. But what’s worse is that a restarted application looses all the state it had in memory.
- …using shared memory can lead to errors, inconsistency, and deadlocks when it’s not protected from concurrent access correctly. And if memory is protected correctly, it may cause contention and increased latency when multiple clients wait to modify the same data simultaneously.
Those with a solid computer science background recognize that memory management is a deep and important subject not to be taken lightly. But in reality many developers learn about it from a hands-on experience of painful and surprising incidents they have inadvertently caused.
How to handle application memory problems:
- Learn how your programming language and web server work. Are there any concurrency features exposed to you as a developer? If yes, how are they supposed to be used?
- When working with web servers, learn about CGI, FastCGI, and general approaches to connection processing (threading, pre-fork, event loop, and their combinations).
- Think twice before turning a stateless service into a stateful one. Usually delegating state management to your database while keeping an application stateless is the way to go.
To learn more:
- Server-side I/O Performance: Node vs. PHP vs. Java vs. Go: the article highlights differences of how some common programming languages process HTTP requests.
- Demystifying memory management in modern programming languages
- What every programmer should know about memory: a hardcore and lengthy read on how memory works at hardware and OS level. I wouldn’t go as far as saying every programmer must know it, but it sure is nice to know, and also is a very curious read!
5.2 Unexpected state: databases
Databases are complex and wonderful beasts. There is a lot to learn about using them correctly. While we won’t go deep in this post, I’d like to list a few questions I believe developers should ask themselves when working with databases. They are not always easy to answer, and the answers might subvert your expectations; especially, in production environments.
-
If I query a database for a data I just inserted, will I get it back? The answer might be “a cautious yes” for single-node databases, and “it depends” in most other cases. Many modern databases employ an eventual consistency model and replicate data asynchronously among the nodes, so that you can’t always get what you just stored - at least, by default. What’s worse, your development environment may not exhibit this behavior because of a different (usually simpler) database server setup and a stable network, so sometimes you can observe replication lag only in production.
-
What if a procedure consisting of multiple queries fails halfway through them? Most developers know to wrap such queries into a single transaction that succeeds or fails atomically. However, transactions aren’t easy even when working with a single database, let alone distributed transactions or transactions across multiple databases. I’ve seen them horribly misused even in simple scenarios (such as handling nested transaction logic). And they get way more complicated when there are more moving parts involved. What if you need to atomically write an operation to a database, clear the cache, and send a notification to another service? Least you can do is consider a possibility of a failure on every step of the data processing pipeline, handle errors with care, and make sure no failure may surprise you when it inevitably happens in production.
-
If a database works on multiple nodes, what happens when one of them fails? Though it doesn’t look like a software problem again, actually failures like these should be accounted for in application layer too. Even if the infrastructure is prepared to handle the outages gracefully, it doesn’t just work magically if your application is unprepared for different failure modes at all. This depends greatly on a specific DBMS, but in general if a minority of the nodes fail, your application should be able to function well or at least serve read-only requests. But oftentimes we, developers, do not plan for partial failures and graceful degradation. With poor error handling and read/write queries arbitrarily interleaved in application code, services fail completely even if they don’t have to.
There are many more things to know about databases, so here are just a few starting points:
- ❤️ Designing data-intensive applications by Martin Kleppmann, my favorite book on the subject which I can’t recommend enough. Also, there’s a lot more amazing content you can find in Martin’s blog and his talks on youtube.
- Things I Wished More Developers Knew About Databases by Jaana Dogan.
- ACID, BASE, and PACELC.
- Use the index, Luke! A guide to database performance for developers.
- Why I love databases.
Also, pay attention to the documentation of the database you’re using and to its developers' blogs. The official documentation is often a much better source of knowledge than random tutorials from the internet. And blogs often reveal the reasoning behind certain decisions and compromises that were made in the database design. For example, if working with redis, I’d recommend a blog by Antirez, its creator.
5.3 Unexpected state: caches
We often see caching as an easy and almost free technique of speeding the service up. Storing a result of an expensive computation or database query must be simple, right? However, while it might be true for some applications (those oftentimes do not need any caching at all!), it is hardly the case for complex and large-scale ones. Using cache carelessly may actually diminish its benefits and bring more problems than it solves.
The fundamental issue when using a cache is that there is no guarantee it is always up to date. Even if cache is cleared diligently every time the primary storage is updated (which may not be as easy as it looks), there’s still a possibility it gets stale. While a write to a primary storage may succeed, an operation to clear the cache may not (unless the cache is kept in the same database system and is updated transactionally). There may also be race conditions, when a cache key is updated by another process that holds an earlier version of the data. So it’s best to assume the cache will inevitably get stale and take measures to mitigate this:
- Always use a limited cache lifetime, and make sure it’s not too long. This way, even when the cache does get stale, it eventually gets resolved by itself without intervention.
- When receiving an object for a subsequent update, always read it from a primary storage, and not from cache. I’ve observed quite a few cases when updates were lost and objects magically reverted to their previous state in production: those are not fun to debug!
Furthermore, there are two typical mistakes programmers make when developing in a local environment:
- Always working with a cache disabled, because it makes debugging a business-logic easier. However, this approach obscures cache control headaches that will emerge in production where caching is enabled. It may turn out cache isn’t being cleared properly or used inefficiently.
- Always working with a cache enabled and warmed-up. In this case, a service might be too slow to serve a request in its initial state, and you might not even know about it. This may lead to timeouts and cascading outages when a cache gets flushed for any reason.
Finding a balance between these approaches in development might require some practice and intuition, as avoiding one of them inevitably leads you to another.
To learn more about caches:
- Amazon Builder’s library: Caching challenges and strategies
- HTTP caching: a very important subject for web developers. Learn how to use
Cache-controlheaders appropriately to avoid serving stale resources and at the same time reduce network traffic.
6. Poor performance
From the perspective of a backend developer, the signs of poor performance include increased latencies, resource consumption, timeouts, unresponding and even crashing processes. Good if they are detected early through monitoring and alerts. But sometimes we only learn about them from the users. For example, there may be just a few clients sharing a particular trait (say, a large account history) that are subject to performance issues. That may not be enough to trigger the alerts, but enough to cause inconvenience.
Among other reasons, this often happens because developers don’t quite realize that in production their code will probably be executed in an unexpected manner. There are two distinct patterns that vary between development and production environments:
First is how frequently the program is executed, usually represented as a number of requests per second. Some consequences of being poorly prepared for this scenario were discussed in the previous sections. Preliminary load-testing and stress-testing should help set expectations from your code at high RPS, and also find and eliminate the bottlenecks.
Second is the size of inputs the program has to churn through. Unless you’re not paying attention to this specifically, it is likely that your dataset size in testing environment is not on par with that in production. Does your local database hold only 100 rows? Sure, a greedy select with no filtering and pagination will work just fine. But what if there are millions of rows in the same table in production? Or what if your file storage can handle 100-kilobyte documents in QA, but crashes when a real client tries to upload a high-resolution video?

An SQL SELECT without a LIMIT
These two patterns can interleave. Sometimes RPS is high, but the payload is processed and transferred quickly. Sometimes RPS is negligible, but the volume of data transmitted over the network per request is huge. And sometimes both come together in one package. It is important to take that into account beforehand, designing and testing a program accordingly. Some workloads require careful optimizations and distributed data processing, while for some a simplest approach works well. It is a good idea to build an approximate model of an expected load profile in the context of your feature: how many active users are there? What is the peak and average load? What is a tolerable latency that my code can add to the total request processing time? How many resources are needed and what might be a bottleneck?
Generally speaking, there is a multitude of things that can hit a service performance under heavy load. Databases, caches, network, disks, CPU and memory: it may require a versatile engineer (or even a team of them) to diagnose and fix. But having a basic understanding of how things work can help to prevent these problems from happening in production in the first place.
How to handle performance problems
- Know the expected load pattern before designing a solution.
- Set up monitoring and learn the relevant tools to be able to quickly find out which component causes the issue. From utilities such as
htop, to services like Zabbix and New Relic - the solution space is vast, be sure you know how to use at least some of those. - Find out which component is slowing the system down before optimizing it. Intuition can be misleading, and things that look like they must be slow are sometimes not the actual bottleneck.
- Employ load testing in your workflow. There are many tools available, but I’d recommend to start simple with something like
siegeork6. - When load testing, try to not just check the latency and status codes, but also ensure that important business logic still works correctly regardless of RPS.
There are some bugs that only reveal themselves under heavy load (like those related to race conditions or database transaction management). In their presence, a code may still run quickly and return
200 OK, while actually losing or corrupting the data. - Learn how your code interfaces with its environment. Code alone is rarely a reason of performance degradation, unless your workload is very specific. Usually the reasons lie in how it interacts with APIs, databases, caches and everything else outside its own memory.
- Database indexes may be a solution. Caches too, but see section 5.3.
To learn:
- Performance Culture and Reflections on software performance: non-technical guides on how to do good performance engineering and introduce it into your development workflow.
- Latency Numbers Every Programmer Should Know
- Performance is a shape, not a number on how performance monitoring has improved over the years.
- Designing for Performance by Martin Thompson. Look up his other talks and posts too!
- Applied Performance Theory
- How do computers and operating systems generally work. This is a subject for a life-long research and I’m nowhere near a full understanding, but a book Computer Systems: A Programmer’s Perspective helped me build a solid foundation.
Putting out fires
Many points have been made about preventing issues in production by improving the development workflow, extensive testing, and so on. Nevertheless, a bitter truth is that nothing will ever prevent 100% of all the possible incidents. Even the best of us make mistakes: just look up the incident reports from major tech companies such as Google, Cloudflare, Microsoft, and the others. While better engineering practices, reproducible environments, testing and monitoring will indeed save you from the majority of the infamous “works on my machine” situations, you still need a backup plan.
So, what should be done when a feature that worked on your machine has been released, and now a production is on fire?
One obvious solution is to roll back a release, if that is an option. Sometimes it’s not: some infrastructural changes are very hard to roll back without outage or data loss. Or if the deployment involved releasing multiple components, rolling them back might just make the incident worse. Anyway, if rolling back is an option, then by all means use it, then take time to reproduce and fix the bug in a development environment.
Another way to minimize damage is to isolate a failure. Depending on what situation allows for, it might be turning a feature off with a feature flag, or maybe switching a project to some kind of a maintenance or read-only mode. Finally, if nothing else is applicable, a quick release that disables a faulty feature usually does the job.
When it comes to actually resolving the cause, it is tempting to act haphazardly. I have caught myself rushing to “just change this one line” or “tune this knob one more time” again and again far too often. Sometimes it works. Oftentimes it doesn’t. A trade-off I developed out for myself is to try and explore a couple of hypotheses quickly, if I feel I have an intuitive solution. In other words, let “system one”, a quick and error-prone part of my brain, do the job - but only for a bounded period of time. And then after it doesn’t help, I force myself to take a tactical retreat and work on the issue systemically. This boils down to reproducing the bug locally, finding a cause, fixing it, writing a test, and rolling the fix out. It may take time and patience, and may even hurt your self-esteem a little. It is a part of our job though, so it helps to make peace with that. Remember that being able to reproduce the problem and rerun the experiments as many times as needed is a luxury unavailable in many other professions.
To learn more about putting out the fires:
- 4 steps to solving any software problem
- Tips for High Availability from Netflix
- Building SRE from scratch
- Incident postmortems explained by Atlassian
A word of caution
Knowing how to avoid problems in theory does not automatically mean you will avoid them. When trying to implement newer practices to stabilize your production environment, it’s possible that in the beginning they may actually make it less stable. Any change comes with a risk, but "…the only man who makes no mistakes is the man who never does anything". Be ready to break a few things along the way, but also to acknowledge the mistakes and learn from them.
Also, no advice is to be trusted blindly. The references under each section of this post are there to describe the subject deeper and better than I did (most of them are taken from a stash of my all-time favorite bookmarks). Some of those references may not always be aligned with each other: there are different opinions! Some solutions may work well for smaller projects, while others are only worth implementing at scale. Find out what works for your team, dig deep, and experiment before rolling out the change in production.
I’m not sure if all the listed recommendations are universally applicable, but they did help me many times in my career. In other words, they worked in my environment. Hope they work in yours too.
